雖然在現代,機器翻譯是個常見的功能(Google翻譯、Bing、...等),但事實上機器翻譯至今仍是個AI-hard的挑戰。
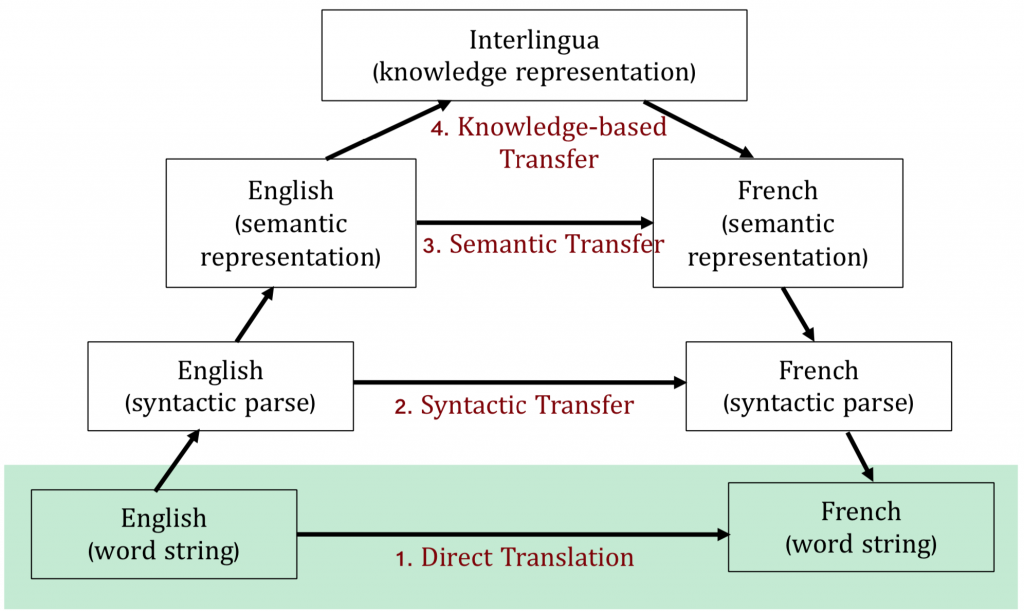
根據Vaquios三角形,翻譯被分為四個等級:(1) 字對字直接翻譯、(2) 句法對句法翻譯、(3) 意思對意思翻譯、以及(4) 知識性翻譯。和人類翻譯相似,初學英文時,我們也常記「這個英文字是中文裡的什麼字」;開始學文法之後,開始能夠照著另一種語言的文法來翻譯自己的想法。後來才有人告訴我們,厲害的人在翻譯中英文的文章時,是讀了一遍之後,不單純考慮文字和文法,而是把文中的意境也列入考量,那就大概是第三層,意思對意思翻譯。歐語系的語文考試(A1→C2)到了C以上的層級時,連該國家的文化背景、地理、歷史都被列入考點,那就比較像是第四層,知識性翻譯。
機器翻譯這個仍在發展的領域目前幾乎都還在第一層,字對字翻譯。機器翻譯主要有word-based、phrase-based和Neural Encoder-Decoder三種處理方式。
Word-based的做法使用字對字比對,根據貝氏定理來算出一句話從一種語言翻譯到另一種語言機率最高的方法。

假設我們要將法文翻譯成英文。首先我們建構英文的語言模型P(e),接著我們也建立一個翻譯用的encoder channel。當一句法文語句進到翻譯系統中時,我們能夠取得最有可能的翻譯結果。
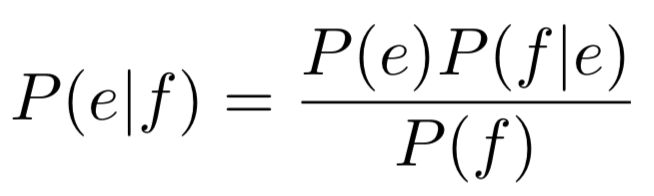
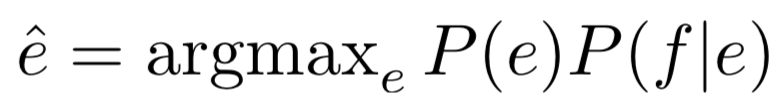
我們來寫一個簡易版的語音翻譯機。我們會使用三個套件:
我們使用的順序非常直觀:讓電腦聽到我們說的話 -> 將人類語言轉換成文字 -> 文字翻譯 -> 將翻譯後的文字轉換成語音播放。 注意:
from googletrans import Translator
import speech_recognition as sr
import pyttsx3
# 初始化翻譯器
translator = Translator()
# 初始化語音辨識
r = sr.Recognizer()
# 初始化文字轉語音
engine = pyttsx3.init()
engine.setProperty('voice', 'com.apple.speech.synthesis.voice.ting-ting')
with sr.Microphone() as source:
print("Please speak:")
audio = r.listen(source)
try:
sentence = r.recognize_google(audio) # 這裡我們使用Google訓練好的語音辨識,Speech Recognition套件中也有其他模型可以用
print("You said: {}".format(sentence))
except:
print("Sorry, can't recognize.")
if translator.translate(sentence).src == 'en':
translated_sent = translator.translate(sentence, dest='zh-CN').text
print("Which means {} in Chinese.".format(translator.translate(sentence, dest='zh-TW').text))
engine.say(translated_sent)
engine.runAndWait()
else:
print("This doesn't sound like English")

今天的ipynb在這裡。


 iThome鐵人賽
iThome鐵人賽